
This report is my final project for the MIT Media Lab Class "Integrative Theories of Mind and Cognition" (also known as Future of AI, and New Destinations in Artificial Intelligence) in Spring 2016. The paper is available here as a pdf
Abstract
Artificial Intelligence performs gradient descent. The AI field discovers a path of success, and then travels that path until progress stops (when a local minimum is reached). Then, the field resets and chooses a new path, thus repeating the process. If this trend continues, AI should soon reach a local minimum, causing the next AI winter. However, recent methods provide an opportunity to escape the local minimum. To continue recent success, it is necessary to compare the current progress to all prior progress in AI.
Escaping the Local Min
Overview
I begin this paper by pointing out a concerning pattern in the field of AI and describing how it can be useful to model the field's behavior. The paper is then divided into two main sections.
In the first section of this paper, I argue that the field of artificial intelligence, itself, has been performing gradient descent. I catalog a repeating trend in the field: a string of successes, followed by a sudden crash, followed by a change in direction.
In the second section, I describe steps that should be taken to prevent the current trends from falling into a local minimum. I present a number of examples from the past that deep learning techniques are currently unable to accomplish.
Finally, I summarize my findings and conclude by reiterating the use of the gradient descent model.
Introduction
Imagine training a pattern matching algorithm (say, a neural network) on the following series of data: 10 data points of the value "good", followed by 5 data points of "bad", another 10 data points of "good" and another 5 data points of "bad." Next, you test the system with 10 data points of "good." What will the algorithm predict the next data points to be?
Obviously, any sufficient pattern matching algorithm would predict an incoming set of "bad" points. Unfortunately, this pattern is the trend of the first 60 years of the AI field1. When the field began, there was a period of success followed by a period of collapse. Then another period of success emerged, but failure soon followed. Currently, we are in a period of great progress. So should we be predicting failure any day now? Is this pattern doomed to continue, or can we understand why it happens and take steps to prevent it?
I believe we can model the field of AI using a technique from within: gradient descent. By modeling the field's behavior with this well understood concept, we can pinpoint the problem with the technique and take steps to ameliorate its downside.
Gradient Descent
Gradient descent is an optimization algorithm that attempts to find the minimum of a function. In gradient descent, a series of steps is taken in the direction of the steepest negative slope. These steps repeat along that path until the direction of the slope changes (which proves a local minimum). The problem with gradient descent is clear: a local minimum is not necessarily the global minimum, since a local minimum is only based on a small period of time. In fact, a given local minimum might be worse than a previously discovered minimum (see Figure 1).
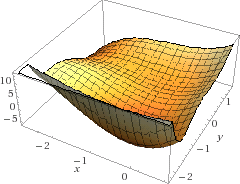 Figure 1: The fallacy of gradient descent can be easily seen here. Starting at (0,0), gradient descent will end at the local minimum near (0,-2), however a far smaller value could be achieved following a path to (-3, 1).
Plot of z=-y^3*(y-2)(y+2) + x(x+1)(x+3) - x^2*y, created with WolframAlpha.
Figure 1: The fallacy of gradient descent can be easily seen here. Starting at (0,0), gradient descent will end at the local minimum near (0,-2), however a far smaller value could be achieved following a path to (-3, 1).
Plot of z=-y^3*(y-2)(y+2) + x(x+1)(x+3) - x^2*y, created with WolframAlpha.
The field of Artificial Intelligence can be modeled with this technique. In this case, the function is loosely understood as the distance that "computer intelligence" is from "human intelligence", over time. That is, as the function approaches zero, computer intelligence approaches human level intelligence. Conceptually, a decreasing slope signifies a progressing state-of-the-art AI, while an increasing slope signifies a lack of progress.
Here, the idea of a local minimum is that the field has chosen a particular path that appeared successful when compared to the recent past. However, the path ran out of areas to improve. Moreover, the path could be worse than a previous minimum — an improvement over the recent past, but a long term dead-end.
In the remainder of this section, I catalog the history of AI falling into local minimum traps.
1960s
Early progress in artificial intelligence was swift and far-reaching. In the years after the Dartmouth Conferences2, there were a series of successes that led to an extremely optimistic timeline.
These successes came largely from attacking a number of challenges using search algorithms. One of the earliest examples of a search based system was SAINT (Symbolic Automatic Integrator)3, a program that could solve integration problems at the level of a college freshman.
Saint was considered the most advanced problem solving system of its time. In the 108-page paper's concluding chapter, Slagle explains insights that he discovered in both natural and artificial intelligence. While Slagle concedes that the program has a limited domain compared to the human mind, he explains that his integration system could solve problems that were advanced than any prior system.
 Figure 2: The goal of the Tower of Hanoi is to move the disks from one ring to another ring, maintaining the smallest-to-largest order of the original.
Figure 2: The goal of the Tower of Hanoi is to move the disks from one ring to another ring, maintaining the smallest-to-largest order of the original.Tower of Hanoi, Wikipedia
Another early success was Newell & Simon's General Problem Solver (gps) 4. This program was able to solve elementary symbolic logic and elementary algebra. The most impressive demonstration of gps was its ability to solve the Towers of Hanoi problem (See Figure 2). Instead of attempting problems that were advanced for humans (such as integral calculus), gps sought to be as general as possible.
The report on gps discusses the system's focus on two techniques: Means-End Analysis (MEA), and planning (discussed later). Mae was the general term Newell et al. used in order to describe the search heuristics in the program. Specifically, the mae algorithms in gps attempted to minimize the difference between the system's current state and its goal state.
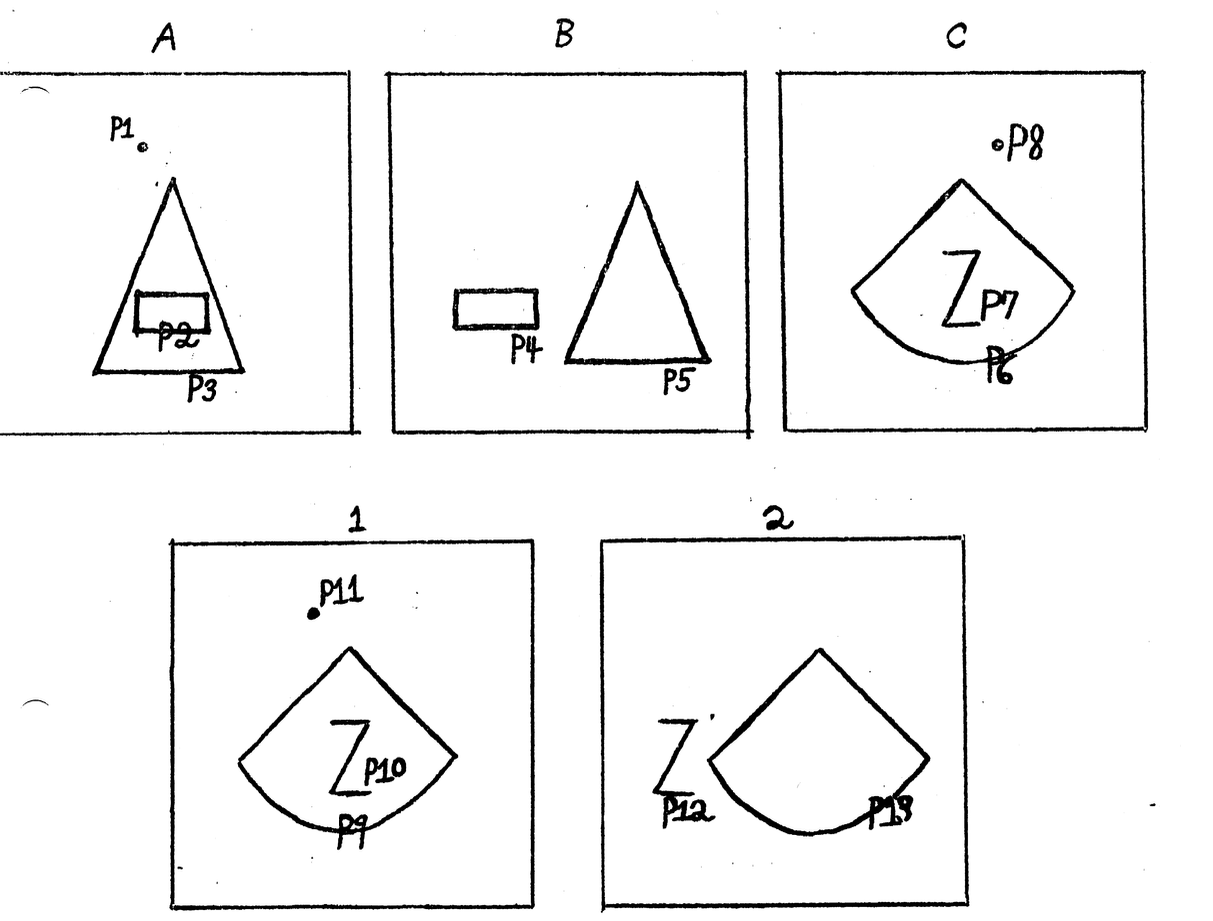 Figure 3: The pictures shown here relate to the type of geometric analogy question that analogy was able to solve.
Figure 3: The pictures shown here relate to the type of geometric analogy question that analogy was able to solve.The question could be asked: Shape A is to shape B as shape C is to which of the following shapes?
Analogy was able to determine the answer: shape 2.
Other successes include Thomas Evans' analogy program and Daniel Bobrow's student program. Analogy5 could solve geometric, IQ-test style analogy problems such as "shape A is to shape B as shape C is to which of the following shapes," as seen in Figure 3.
Meanwhile, student6 was able to solve word-algebra problems at a high school level. These early successes, many of which were at MIT, along with a large ARPA grant, led Marvin Minsky and John McCarthy to found the MIT AI Lab in the late 1960s.
All of these examples (and more) showed the field of Artificial Intelligence to be progressing well. This progress led to widespread optimism. In 1967, Minsky reportedly said "within a generation ... the problem of creating 'artificial intelligence' will substantially be solved."7
It might seem likely that Minsky quickly loosened his prediction. In fact, the opposite occurred. In 1970, three years and many small successes later, Minsky quickened and expanded his prediction, saying:
The 1960s marked a period of highly successful gradient descent. Of course, gradient descent inevitably leads to a local minimum. In this first golden age of AI, that local minimum hit the field in the mid 1970s and has since been known as the First AI Winter.
#### The First AI Winter Both progress and funding slowed in the mid 1970s. Here, I provide a few examples of the decreased level of success and the reduction of funding that lead this period to be known as the AI Winter. I argue that while there were a number of contributing factors to this winter, lack of diversity in research paths was a leading reason. Simply put, the field hit a local minimum — no further progress could be made without changing course. The Lighthill report9 was the first clear indicator of the AI Winter. The report, released in 1974, conveyed a largely negative outlook on the first quarter century of the field. Lighthill states "Most workers in AI research and in related fields confess to a pronounced feeling of disappointment in what has been achieved in the past 25 years." He goes on to chronicle examples and reasons for this disappointment. A fascinating recording of a debate between Lighthill and John McCarthy concisely summarizes many of these reasons.10 The overarching theme of Lighthill's pessimism comes from the failure of researchers to account for combinatorial explosion. That is, problems that can be solved within a narrow domain do not scale up to real-world problems due to the branching factor of the search trees (see Figure 4).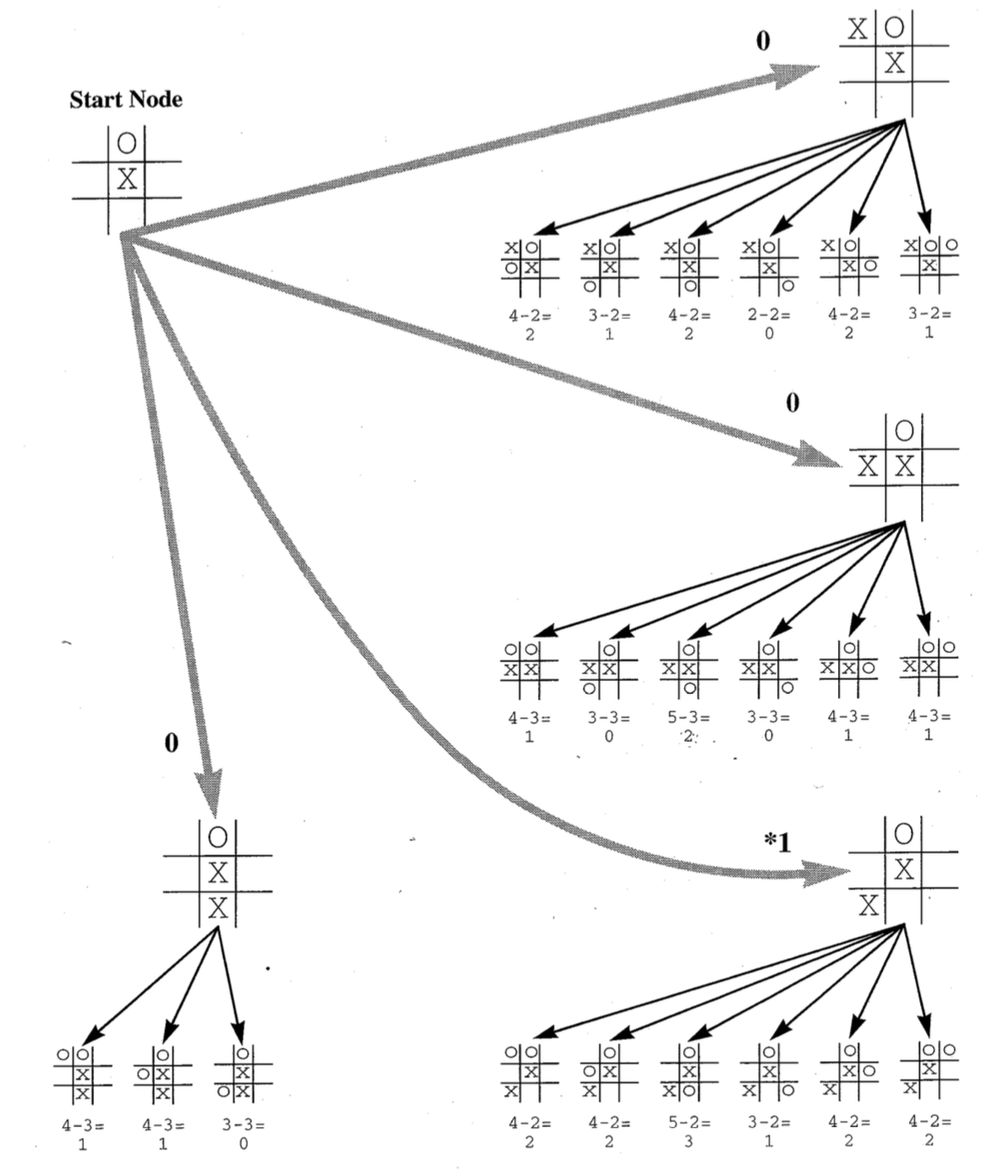 Figure 4: This figure shows the branching factor of tic-tac-toe. It is clear that even though tic-tac-toe is a very simple game, the exponential nature causes massive increases over time. This game has a maximum branching factor of 8. The game Go has a branching factor of 250. The branching factor for real world decisions can be thousands. Clearly, simple search quickly breaks down.
Figure 4: This figure shows the branching factor of tic-tac-toe. It is clear that even though tic-tac-toe is a very simple game, the exponential nature causes massive increases over time. This game has a maximum branching factor of 8. The game Go has a branching factor of 250. The branching factor for real world decisions can be thousands. Clearly, simple search quickly breaks down.Game Play, Charles Dyer
Another report, written by the Automatic Language Processing Advisory Committee11, is also known to have caused a dramatic decrease in funding. Early in the report, the recommendations suggest that the National Science Foundation fund four to five centers at $650,000 each. However readers of the report focused on the conclusion that human language translation was far more cost effective, thus halting AI funding in machine translation.
Fortunately, the winter did not last for an extended period. By the early 1980s, the field had regrouped, and sought a new path towards progress.
1980s
A focus on expert systems and knowledge bases sparked a resurgence of AI in the early 1980s. These systems were commercially viable — a first for AI systems — which led to a large influx of AI funding from private corporations.
Programs known as expert systems used specific domain knowledge to answer questions and solve problems. Two of the most well known expert systems include xcon and Cyc.
Xcon stands for eXpert CONfigurer, but the system was commonly known as R1. R1 was built at Carnegie Mellon and used by Digital Equipment Corporation. This AI reportedly saved the company $40 million annually.
While the system saved millions, R1 was far from optimal. The limitations became increasingly obvious. A 1984 report in AI magazine concluded with a poignant observation: "Even revolutionary ideas and technologies do not solve every problem."12
In the same year, Douglas Lenat created Cyc. The goal of Cyc was to have human-like reasoning by maintaining an enormous knowledge base. Lenat's plan involved decades of development, and the project is still ongoing.
Other successes from this time period include Deep Thought13 (a chess solving system that won the 1988 North American Computer Chess Championship) and soar14 (a cognitive architecture with the goal of performing the "full range of cognitive tasks").
Once again, the successes of the time did not last. Researchers and institutions soon found the fragility of early knowledge based systems. The field ran out of progress on the expert systems path — it reached a local minimum.
The Second AI Winter
 Figure 4: This article in the March 4, 1988 edition of the New York Times explains the number of commercial failures of expert systems.
Figure 4: This article in the March 4, 1988 edition of the New York Times explains the number of commercial failures of expert systems.The table shows substantial losses and layoffs at Teknowledge, Intellicorp, Carnegie Group, and Interencem, which are all expert-system based companies.
This PDF version is behind a paywall here.
It is available in text form publicly, here.
The second AI winter felt very similar to the first winter. Over optimistic views, a reduction in investment, and a lack of new directions all led to a period (from approximately 1987 to 1993) known as the second AI winter.
Overoptimism was the first major reason for this winter. One clear example can be seen in the Fifth Generation Computer Systems (fgcs). Fgcs15 was a 1982 initiative developed by Japan's Ministry of International Trade and Industry. The goals of this initiative were far reaching. It sought to act as a supercomputer that could translate languages, interpret pictures, and reason like human beings. After 10 years and $400 million later, the project failed to meet its goals and was thus canceled.
Both public and private institutions reduced investment after a series of failures. As seen in Figure 5, three different groups of AI focused companies all had dramatic setbacks. First, AI development tool companies suffered many quarters of losses which resulted in laying off 10% to 20% of the workforce. Second, machine manufacturers, such as Symbolics16 and Xerox, pivoted their goals and reorganized their companies to reduce the focus on Lisp machines. Finally, expert system applications suffered in sales and announced layoffs.
This lack of progress, lack of funding, and commercial failure can easily be explained by comparing the overly optimistic goals of these systems to the implementation details. After domain specific tasks had been mastered, many companies attempted to use expert systems and large knowledge bases to create flexible, general AI systems. However, the fragility and domain specific nature of these methods was not obvious. When more ambitious goals were attempted, they failed again and again.
Eventually, the field exited the winter and reset. The period of time after this winter ended can be categorized as the modern day boom of artificial intelligence.
Modern Day
There is constant news of AI successes in modern times. In 1997, Deep Blue17 (a chess AI system) defeated the reigning world chess champion. In 2005, a Stanford robot drove autonomously for 131 miles, winning the DARPA Grand Challenge18. In 2011, IBM's Watson19 system competed on the TV game show Jeopardy and defeated both human opponents.
Consumer electronic companies have recently popularized voice based AI assistants. Apple released Siri on iOS in 2011. Google released Google Now on Android in 2012. And Amazon released Echo, voice assistant hardware product which operates hands free, in 2015.
The most recently publicized breakthrough was Google DeepMind's AlphaGo20. AlphaGo is a system that plays the game Go, and it defeated one of the highest ranking human Go players in 2016. AlphaGo mastered Go between 5 to 10 years before many people predicted an AI to be capable of such a high level of play.
This string of success is incredible. However, if the historical pattern continues, an AI winter should be imminent.
The Next AI Winter
Is the next AI winter rapidly approaching? It seems improbable given all of the recent successes. However, it also seemed improbable in 1968 and in 1985, and the winters came nevertheless.
There are many optimistic predictions about the future of the field, as there have always been. Predictions for 2025 include:21
- widespread use of self-driving cars (Vint Cerf)
- food will be raised, made, and delivered robotically (Stowe Boyd)
- "AI and robotics will be close to 100% in many areas" (Marc Prensky)
It's possible to imagine the headlines of the next AI winter. Pretend the year is 2019, and the following stories appear on a news site:
- After self-driving cars fail to work in many states, tech companies cancel self driving car plans
- Humans still prove to be much more efficient than robots
- Virtual assistants fall short on understanding complex demands
This would not be a shock although it would be a sign that the field was once again in an AI winter.
However, the next winter is not inevitable. The field can prevent itself from falling into the local minimum trap by ensuring it can do everything that has been possible in the past two AI booms.
In this section, I have shown that a gradient descent & local minimum method is a realistic model to explain the previous 50 years of artificial intelligence. I have cataloged successes of the 1960s and 1980s, as well as the failures of the two AI winters. I have provided examples of recent success, and suggested that a future winter is possible but not inevitable.
In the next section, I suggest steps that should be taken to prevent the field from falling into another local minimum.
Deep Learning Checklist
This modern day success is largely the result of advances in deep learning. Hinton22 astonished the world with deep neural networks in 2012. Since then, the rise of neural networks (NNs) have taken over as the dominant technique for state-of-the-art AI systems. Unfortunately, there are still many domains for which neural networks have great difficulty.
Deep learning's incredible advantage is its superiority is perception: NNs are the ultimate pattern matching device. In lots of cases, NNs can already find patterns in data at a superhuman level.
In the previous section I explained that the AI field can become trapped in a local minimum if it focuses too heavily on short term progress by only exploring the strength of a given technique.
So, if the AI field is doomed to repeat its mistakes, then the research focus is clear. Deep learning researchers should keep working to make object detection in images nearly perfect. Hinton should work on going from a 15% error rate on ImageNet data to 0.5% error rate. NNs should be developed to find patterns in the stock market to become rich and optimize engagement on social networking websites.
Of course, the field would then be trapped in a local minimum. Fortunately, the statistical, neural network approach23 can avoid this pitfall. Because NNs are biologically inspired systems, they are architecturally more similar to human thinking than any previous technique. Combining this human-like architecture with the understanding that NNs are Turing Complete, it is possible that NNs can be used as a substrate for all AI systems. That is, all future systems can be built on top of a statistical network base layer.
To prove that the state-of-the-art deep learning techniques are in-fact superior to all prior systems, and to show that NNs can be used as a substrate for future programs, it is necessary to apply NNs to previously developed or proposed tasks.
In the remainder of this section, I describe three different categories of AI research that currently do not implement a statistical or NN approach. For each example, I first explain the work that has previously been done on the topic. Then, I describe the value that is to be gained from a successful implementation. Finally, I inventory research that appears to have taken steps — or at least shows promise in taking steps — towards the given topic.
The three categories I describe are: logic systems, Minsky's multiplicity, and story understanding. Each is presented in depth below.
Logic Systems
The first category to investigate is generic symbol manipulation. Symbolic systems are based on high level representations of information with explicit rules. An in-depth look at these early programs, such as saint, is discussed on in the section 1960s, above. Figure 6 shows a list gathered by Marvin Minsky of these early successes.
 Figure 6: A screenshot of a slide from Marvin Minsky's talk Artificial Intelligence and the Future of the Human Mind. The slide shows a list of AI successes from the 1960s and 1970s. Nearly all of the results on the list are rule-based logic systems.
Figure 6: A screenshot of a slide from Marvin Minsky's talk Artificial Intelligence and the Future of the Human Mind. The slide shows a list of AI successes from the 1960s and 1970s. Nearly all of the results on the list are rule-based logic systems.
A recording of this 2007 talk can be seen here.
Fifty years after Slagle's saint program, the state-of-the-art calculus systems essentially the use the same methodology. The program understands explicit rules24 that were explicitly programmed by the developer. The system then searches for rules it can apply to the current state in an effort to simplify the integral. Because the knowledge representation is at a symbolic level, and the number of rules is limited: there is no need for an integration system to learn rules overtime.
However, it would be useful to have a neural network that is able to perform symbolic algebra. There are two clear reasons for this desire. First, this hypothetical system would demonstrate that neural networks can be used as a substrate for previously-achieved AI systems. Second, a neural network that could perform symbolic algebra would, by definition, be able to manipulate symbols. This would show that high level knowledge representations can be grounded25 in statistical models.
Two research findings show promise toward this goal. First, a 2010 paper titled "Neural-Symbolic Learning and Reasoning"26 outlines the goals and directions of this space. This paper describes deep learning systems that have been developed to learn first-order logic rules within a NN. This is done by encoding symbols and logic terms as vectors of real numbers.
Second, Alex Graves' "Neural Turing Machine" 27 is a neural network system that can use external memory to hold additional information during computation. Early results have shown that the system can learn simple commands such as copying, sorting, and associative recall. These commands can be used as building blocks for future symbol manipulation, which could enable NN systems to be extremely generalizable symbolic manipulators.
These systems show progress, but they are still quite far from the symbolic manipulators of the 1960s. A heavy research focus should be placed on demonstrating that deep learning can succeed in this area.
Minsky's Multiplicity
Marvin Minsky explored a broad range of topics over the course of his career. In two distinct occasions, Minsky provided interesting categorization systems. The first is a list of five areas of heuristic problem solving. The second is a list of the six layers of thinking. I will refer to these two classifications as Minsky's Multiplicity28, though I will address each individually.
The first category to discuss is the list of areas of heuristic problem solving. Minsky first explains these five areas in his groundbreaking 1960 paper, "Steps Towards Artificial Intelligence"29. In this paper, he explains that search, pattern recognition, learning, planning, and induction are five distinct but crucial areas of problem solving.
The strongest advantage of neural networks is in the area of pattern recognition. In the pattern recognition section of Minsky's 1960 paper, he suggests that bayesian nets could be a useful tool in mastering pattern recognition.
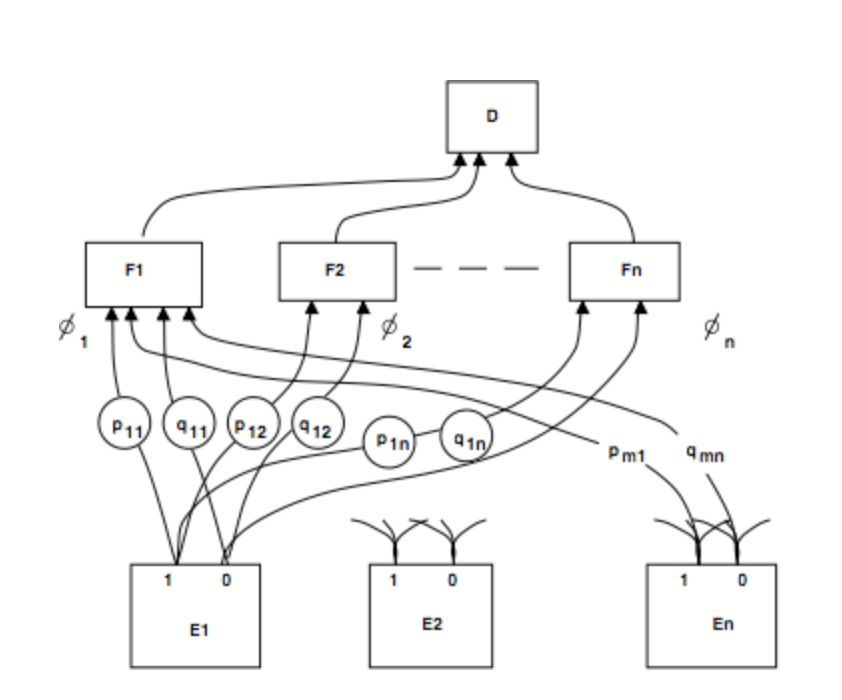 Figure 7: This diagram is an early bayesian network architecture from Minsky's seminal 1960 paper.
Figure 7: This diagram is an early bayesian network architecture from Minsky's seminal 1960 paper.
Today, it is clear that neural networks are dominant in pattern recognition and learning. NNs are able to find imperceivable patterns in data. Also, NNs do not require hard coded rules, the programs are able to learn based on a vast amount of training data, through backpropagation. While it is obvious that neural networks will continue to become better at pattern recognition and learning, it is worth considering the other 3 areas.
In terms of search, the state of NN searching is dependent on the definition of search. Minsky's definition was not rigid: "[if] we have a means for checking a proposed solution, then we can solve the problem by testing all possible answers. But this always takes much too long to be of practical interest." There are a number of NN architectures that show promise in the area of search. James Atwood and Don Towsley recently presented "Search-Convolutional Neural Networks" 30 (SCNN). This architecture defines features by traversing a local graph by breadth-first search and random walks. Another paper focuses on the more traditional use of the term search: "Using Neural Networks for Evaluation in Heuristic Search Algorithm" 31 is a NN system that develops its own search heuristics instead of relying on hard-coded search algorithms such as A*.
The areas of planning and induction are often considered to be at a higher level of cognition. Planning breaks down complex problems into subproblems, while induction is the progress of using previous knowledge to come to a conclusion about a related but different scenario. Both areas are often discussed at the symbolic level. Therefore, to progress in these sectors of intelligence, NN must achieve symbolic manipulation abilities discussed in the previous section.
 Figure 8: This diagram displays the 6 layers of Minsky's model. Innate and instinctive urges and drives are realized in the bottom layers. Whereas values, censors, ideals, and taboos are understood at the upper layers.
Figure 8: This diagram displays the 6 layers of Minsky's model. Innate and instinctive urges and drives are realized in the bottom layers. Whereas values, censors, ideals, and taboos are understood at the upper layers.
The second categorization that Minsky developed included six layers of thinking, seen in Figure 8. These six layers were initially defined and described in Emotion Machines32.
Cognitive architectures, such as The MicroPsi Project33 and Leabra 34 attempt to model all of cognition. These systems strive to reach all six layers. However, neural networks might be able to develop these levels without the need for an entire static architecture.
Both Minsky's layers and neural networks are hierarchical. Therefore it would make logical sense that basic NNs can most easily implement the lowest levels of Minsky's layers. Conversely, NNs would most struggle with the highest level layers, as the system would need a successful implementation of all layers below the goal layer. This logic is accurate.
Modern deep learning systems all "think" at the reactive (base) layer. The neural networks have automatic responses based on perceived information about the world. It is possible to make the argument that more advanced deep learning programs have deliberative thinking. However it would be hard to ague that any NN reaches reflective thinking. No modern system is able to "reflect on and manage deliberative activity". 35
This demonstrates that there is universal agreement that neural networks can, so far, only perform at the two lowest levels of thinking. However, reflective thinking is within reach. If neural networks were able to report what features had been detected in the hidden layers of the net, then the NN would be able to explain the reason for its output. This would enable deep learning to reach at least the third layer of cognition.
Minsky's multiplicities provide a straightforward benchmark to compare neural network systems to other techniques. For deep learning to succeed, it must operate on all 6 layers of cognition and be able to perform all five types of problem solving heuristics.
Story Understanding
Understanding language is a critical task to any sufficiently advanced system. Claims of success in language understanding first started in 1970, when Terry Winograd developed shrdlu. 36
This program was able to carry on a dialog about a blocks-world environment with a user. However, critics of this system argued that the system did not truly understand language — that the system was not actually "thinking." This debate was later formalized in a 1980 paper by John Searle37. In this paper, Searle defined the Chinese Room Argument.
Since that time, two prominent professors have attempted to more formally understand computational language understanding. First, Noam Chomsky, a linguistic and cognitive scientist, has described the "merge" operation 38, which he believes is crucial to human language. The merge operation is the ability — which is unique to humans — to take two concepts and form a new concept, indefinitely. In his recent book, Why Only Us 39, Chomsky explains the evolutionary plausibility of this uniquely-human capability.
In work that pairs well with Chomsky's merge operation, Patrick Winston has spent decades working on computational story understanding. Winston's work largely centers around the Strong Story Hypothesis40, which states that storytelling and story understanding have a central role in human intelligence.
Winston's implementation of his ideas is a program known as Genesis41. Genesis is able to understand stories and answer questions based on a very small amount of training information. For example, when given the story of Macbeth (by William Shakespeare), Genesis is able to answer the question "why did Macduff kill Macbeth?" and respond based on perspective. From a personality perspective, Genesis can respond "Macduff kills Macbeth because he is vicious." From a commonsense perspective, Genesis answers "... Macduff kills Macbeth, probably because Macduff wants to kill Macbeth and Macduff is vicious." From a concept level, the response is "Macduff kills Macbeth is part of acts of Revenge, Answered prayer, Mistake because harmed, Pyrrhic victory, and Tragic greed."
With these type of question and answering capabilities, Winston makes the argument that Genesis understands stories at a human level. The argument is also made that Genesis operates on all levels of Minsky's six layer model (described in the previous section).
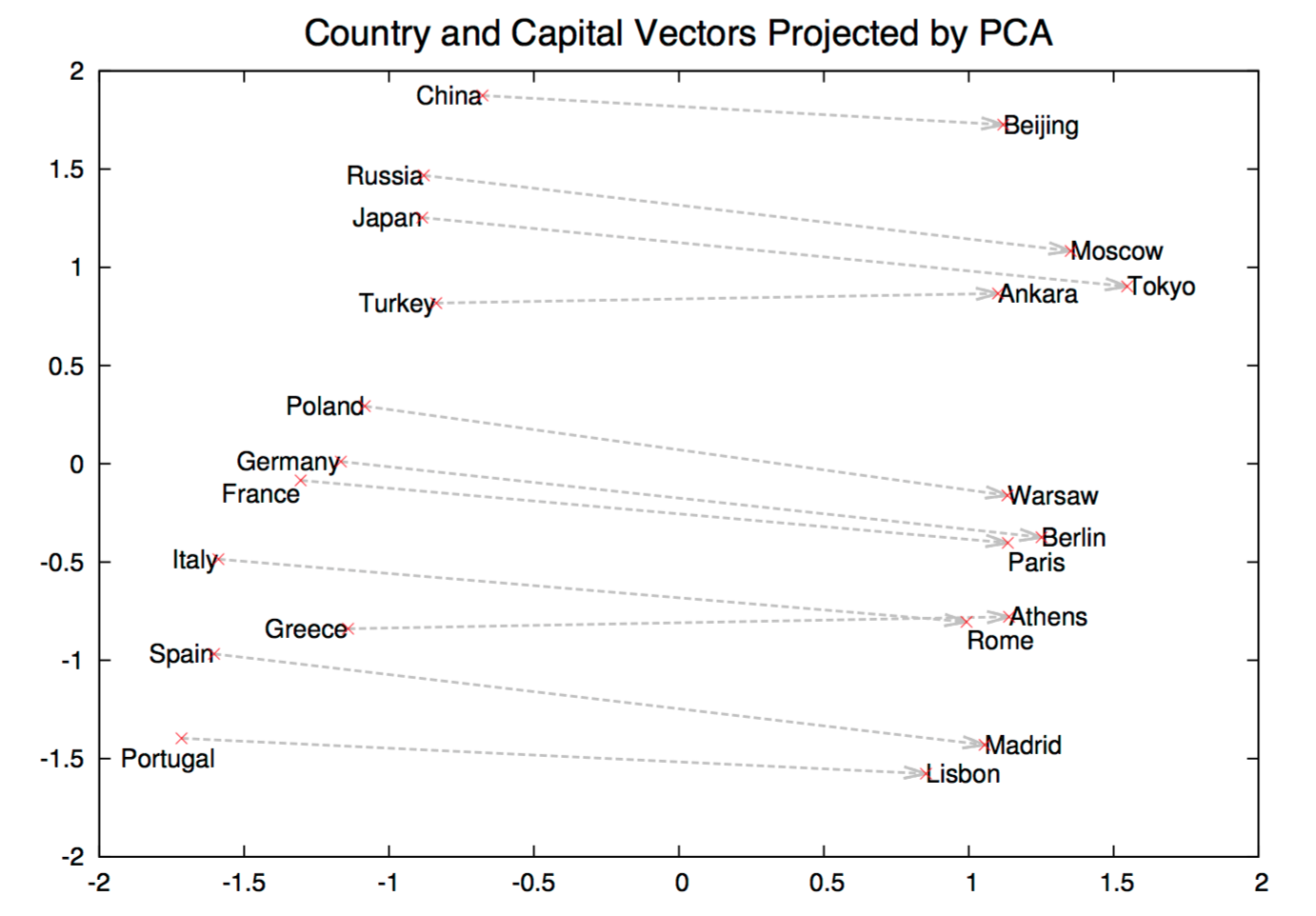 Figure 9: This figure shows a 2 dimensional view of countries and their capitals. The projection necessary to translate from a country to a capital is clear. (This figure is referenced from Mikolov et. al.)
Figure 9: This figure shows a 2 dimensional view of countries and their capitals. The projection necessary to translate from a country to a capital is clear. (This figure is referenced from Mikolov et. al.)
No deep learning system has come close to this level of cognition. However, there are introductory steps that show promise. Recent statistical modeling, namely word2vec, is able to take symbolic language and convert words into a vector-space, allowing for computational manipulation. This vectorization of information enables compositionally22 of concepts. For example, the vector transformation of Madrid - Spain + France results in the vector Paris. Therefore, the knowledge representation understands the Madrid - Spain to be the concept of a country capitol. Then the capital concept is combined with France to produce the capital of France, which is Paris.
This aligns well with Chomsky's merge operation. Multiple concepts are formed together to produce a new concept. Since the new concept remains a distributed, vector representation, the new concept can be merged with other concepts indefinitely.
Recurrent Neural Network architectures also show promise in an attempt to computationally model language. Bengio43 has described the potential for sequential understanding, and recent commercial successes have progressed the field. However, major huddles still lay ahead.
To show that neural networks are a plausible fundamental substrate, two major accomplishments need to be made. First, neural network natural language processing must increase its accuracy when training data is extremely low. Genesis is able to learn stories in under 100 sentences, from a collection of under 25 stories. Today's best systems still use databases of millions of entries. Second, these systems must be able to operate at the upper levels of Minsky's 6 layers. Once the reflective and self-reflective levels are reached, the argument for deep learning models as a base layer will become much stronger. Further work on both of these areas is much needed.
Contributions
In this paper, I have argued that the field of Artificial Intelligence performs a type of gradient descent. I have outlined the periods of success, followed by periods of realization that the current technique has major limitations.
I have explained that deep neural networks are a computationally plausible solution for a substrate that can enable all future AI systems. I explained three areas of research in Artificial Intelligence that deep learning has not solved. For each area, I have described the current state of the art, the reason that area is critical to AI, and what deep learning methods show promise for future success.
After many decades of research, the field has the tools to develop a substrate that can power all AI systems. However, if the field only focuses on the easy and obvious problems, the next AI winter will certainly ensue. To continue progress towards general artificial intelligence — and to escape the local minimum — the deep learning community must focus on the tasks that are far from being reached, but necessary for long term success.
Updates
A lively discussion of this paper occurred on Hacker News, check out the discussion over there.
Thanks to some friendly readers, I've made a small number of minor edits since publishing this work. Those changes will be reflected immediately on this page but will not be reflected in the PDF version. As I make modifications, those changes will be listed here:
- Removed Danny Hillis as the founder of Symbolics (he actually founded Thinking Machines) [5/30/16]
-
Of course, this trend is a simplification. A field of academia is not binary in its progress. However, it is a useful simplification to understand periods of significant improvement compared to periods of stagnation. ↩
-
The Dartmouth Conferences took place at Dartmouth College in 1956. The complete name of the event was the Dartmouth Summer Research Project on Artificial Intelligence. It spanned 2 months and is widely regarded as the founding conference of the field.
McCarthy et al. [2006] ↩ -
James Robert Slagle. A heuristic program that solves symbolic integration problems in freshman calculus, symbolic automatic integrator (saint)., 1961. URL ↩
-
Allen Newell, John C Shaw, and Herbert A Simon. Report on a general problem-solving program, 1959. URL ↩
-
T.G Evans. A heuristic program to solve geometric analogy problems, 1962. URL ↩
-
Daniel G Bobrow. Natural Language Input for a Computer Problem Solving System. PhD thesis, Massachusetts Institute of Technology, 1964. URL ↩
-
Daniel Crevier. AI: The Tumultuous History of the Search for Artificial Intelligence. Basic Books, Inc., New York, NY, USA, 1993. ISBN 0-465-02997-3 ↩
-
Brad Darrach. Meet shaky, the first electronic person, 1970. URL ↩
-
Sir James Lighthill. Artificial Intelligence: A general survey, 1974. URL ↩
-
Sir James Lighthill and John Mc- Carthy. The lighthill debate, 1973. URL ↩
-
Language and machines: Computers in translation and linguistics. URL ↩
-
Stephen Polit. R1 and beyond: AI Technology transfer at digital equipment corporation. AI Magazine, 5(4):76, 1984. URL ↩
-
Hans Berliner. Deep thought wins fredkin intermediate prize. AI Magazine, 10(2), 1989. URL ↩
-
John E. Laird, Allen Newell, and Paul S. Rosenbloom. Soar: An architecture for general intelligence. Artificial Intelligence, 33, 1987. URL ↩
-
Andrew Pollack. ’fifth generation’ became japan’s lost generation. New York Times, 1992. URL ↩
-
John Abell. March 15, 1985: Dot-com revolution starts with a whimper, 1985. URL ↩
-
Murray Campbell, A Joseph Hoane, and Feng-hsiung Hsu. Deep blue. Artificial intelligence, 134(1):57–83, 2002. URL ↩
-
DARPA Grand Challenge 2005 was a competition hosted by DARPA in order to promote the development of fully autonomous ground vehicles. ↩
-
AI Magazine. The AI Behind Watson — the technical article. AI Magazine, 2010. URL ↩
-
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016. URL ↩
-
Aaron Smith and Janna Anderson. Ai, robotics, and the future of jobs, 2014. URL http://www.pewinternet.org/files/2014/08/Future-of-AI-Robotics-and-Jobs.pdf ↩
-
Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing sys- tems,pages1097–1105,2012. URL ↩
-
In this section, my use of the term "statistical" is in a neural network sense. Also, my use of the term "neural networks" encompass all subcategories and tangential concepts such as convolutional neural networks, recurrent neural networks, deep belief networks, and the like. ↩
-
For example, the power rule or integration by parts. ↩
-
Artur d’Avila Garcez, Tarek R Besold, Luc de Raedt, Peter Földiak, Pascal Hitzler, Thomas Icard, Kai-Uwe Kühnberger, Luis C Lamb, Risto Miikkulainen, and Daniel L Silver. Neural-symbolic learning and reasoning: contributions and challenges. 2015. URL ↩
-
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014. URL ↩
-
Minsky's Multiplicity is not a widely used term for these two topics. In fact, I coined this term specifically for this paper, as no paper that I am aware of has discussed both of these classifications together. The term is a play on words, as Minsky provides multiple multiplicities. ↩
-
Marvin Minsky. Steps toward artificial intelligence. Proceedings of the IRE, 49(1):8–30, 1961. URL ↩
-
James Atwood and Don Towsley. Search-convolutional neural networks. CoRR,abs/1511.02136,2015. URL ↩
-
Hung-Che Chen and Jyh-Da Wei. Using neural networks for evaluation in heuristic search algorithm. In Twenty-Fifth AAAI Conference on Artificial Intelligence,2011. URL ↩
-
Marvin Minsky. The Emotion Machine: Commonsense Thinking, Arti- ficial Intelligence, and the Future of the Human Mind. Simon&Schuster,2006. ISBN0743276639. URL ↩
-
Randall C. O’Reilly. The leabra cognitive architecture. URL ↩
-
There does exist a system that claims to operate on all 6 layers, which I discuss further in the next section. ↩
-
Terry Winograd. Procedures as a representation for data in a computer program for understanding natural language. Technical report, Massachusetts Institute of Technology, 1971. URL ↩
-
John R Searle. Minds, brains, and programs. Behavioral and brain sciences, 3(03):417–424, 1980. URL ↩
-
Precisely, Chomsky describes this operation: "an indispensable operation of a recursive system [...] which takes two syntactic objects A and B and forms the new object G={A,B}" ↩
-
Robert C. Berwick and Noam Chomsky. Why Only Us. The MIT Press, 2016 ↩
-
Patrick Henry Winston. The strong story hypothesis and the directed perception hypothesis. Proceedings of the AAAI Fall Symposium on Advances in Cognitive Systems, 2011. URL ↩
-
Patrick Henry Winston. The genesis story understanding and story telling system: A 21st century step toward artificial intelligence. Memo 019, Center for Brains Minds and Machines, MIT, 2014. URL ↩
-
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013. URL ↩
-
Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jurgen Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001. URL ↩